Gratis OCR-software om tekst uit beeldbestanden en PDF-items te halen. Een grafische user interface (GUI) voor de Tesseract OCR-engine.
De applicatie is eenvoudig te installeren en, wat nog belangrijker is, vrij om, open-source en 100% adware en spyware vrij te gebruiken.
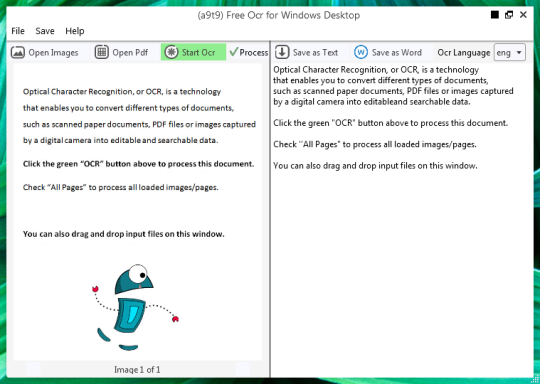
U kunt een afbeelding of PDF-bestand te openen. De inhoud van de bron bestand wordt weergegeven in het linker venster. Als uw document als meer dan één pagina, of als u documenten met meerdere pagina geopend, gebruikt u de pijlen op de bodem om te schakelen tussen hen,
Je begint het OCR door te klikken op de groene knop OCR, en je zal het resultaat in de tweede rechter venster te zien. Uitgang tekst kan worden opgeslagen als een tekstbestand of Word-document.
Helaas is de conversie kwaliteit is niet zo groot. Achter de scène gebruikt het de Tesseract open-source OCR-engine. De kwaliteit varieert van taal tot taal -. Dus ga je gang en test of het voldoende is voor uw behoeften
Voor software-ontwikkelaars en geeks: De Vrije OCR voor Windows Desktop tool is in wezen een grafische gebruikersinterface front-end (GUI) voor de Tesseract OCR-engine. De volledige broncode is beschikbaar (GPL licentie).
De OCR-engine van de software ondersteunt de volgende OCR-taal: Engels, Frans, Italiaans, Duits, Spaans, Braziliaans Portugees en Nederlands. Vanaf versie 3 kan herkennen Arabisch, Bulgaars, Catalaans, Chinees (vereenvoudigd en traditioneel), Kroatisch, Tsjechisch, Deens, Nederlands, Engels, Duits (standaard en Fraktur script), Grieks, Fins, Frans, Hebreeuws, Hindi, Hongaars, Indonesisch, Italiaans, Japans, Koreaans, Lets, Litouws, Noors, Pools, Portugees, Roemeens, Russisch, Servisch, Slowaaks (standaard en Fraktur script), Sloveens, Spaans, Zweeds, Tagalog, Tamil, Thai, Turks, Oekraïens en Vietnamees.
Reacties niet gevonden