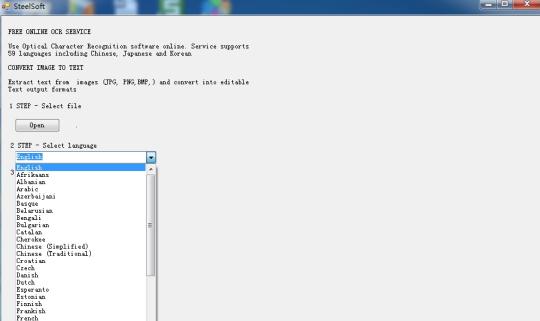
Tekst herkennen van beelden met behulp van de Tesseract OCR-engine op basis van de cloud-technologie.
Gebruik Optical Character Recognition software online. Dienst ondersteunt 59 talen, waaronder Chinees, Japans en Koreaans. Uittreksel tekst uit afbeeldingen (JPG, PNG, BMP, TIF) en omzetten naar bewerkbare tekst output formaten.
Het is gebaseerd op cloud-technologie, en zeer beroemde OCR-engine (Tesseract OCR Engine), dus er is slechts honderden KB in grootte, maar het kan tekst extraheren in 59 talen, van de beelden.
Het ondersteunt meer talen: Bulgaars, Catalaans, Tsjechisch, Deens, Nederlands, Engels, Fins, Frans, Duits, Grieks, Hongaars, Indonesisch, Italiaans, Lets, Litouws, Noors, Pools, Portugees, Roemeens, Russisch, Servisch, Slowaaks, Sloveens , Spaans, Zweeds, Tagalog, Turks, Oekraïens, Vietnamees etc
Wat is nieuw in deze release:..
Versie 5.0 bevat verbeteringen UE

Reacties niet gevonden