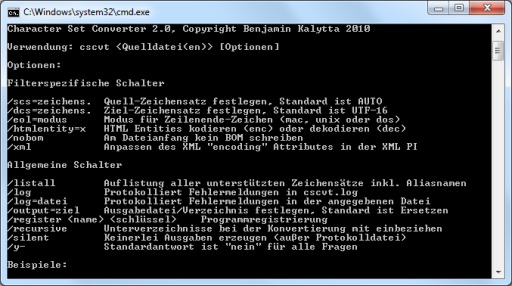
Dit is een command line conversie tool om te converteren van het ene personage ingesteld naar de andere binnen tekstdocumenten. Het ondersteunt bijna alle ISO 8859 tekensets, alle DOS tekensets, belangrijkste Apple tekensets en de meeste Windows-tekensets (non Aziatische). Het kan ook converteren of UTF-8, UTF-16 en UTF-16BE (Big Endian), UTF-32. Het detecteert automatisch de meeste van de ondersteunde tekensets. Andere ondersteunde tekensets zijn AtariST, KOI8-R, KOI8-U, KZ-1048, NeXT, diverse EBCDIC-, in totaal meer dan 60 tekensets worden ondersteund. De tool is gebaseerd op www.unicode.org mapping tabellen en geen Windows API niet gebruiken voor conversie. Versie 2 werd volledig opnieuw ontworpen en is nu een command line gebaseerde tool die hetzelfde karakter sets als eerste versie ondersteunt, maar ondersteunt ook onbeperkt bestandsgrootte omdat er geen in-memory conversie wordt gedaan. Ook niet volledig UTF-8 te voldoen (te lange sequenties) bronbestanden worden ondersteund zonder dat "ongeldig teken" waar mogelijk. Er zijn verschillende toepassingsgebieden. Het omzetten van oude mainframe computer bestanden (dwz EBCDIC- geconverteerd of DOS tekstbestanden) in de hedendaagse machine (PC) leesbare formaten, het omzetten van de database dumpt in meerdere talen compatibel UTF-8-indeling, het voorbereiden van oude enkele websites taal voor meertalige lokalisatie zijn slechts drie voorbeelden.
Wat is nieuw in deze release:
Versie 2.017.8: autoamtically tekenset detectie; Bug Fixes; CSV formatted uitgang
Wat is nieuw in versie 2.017.2:.
autoamtically tekenset detectie
Bug Fixes
CSV formatted uitgang
Beperkingen
30-dagen trial
Reacties niet gevonden